
Scan the QR code to download the app
Open the camera app to scan the QR code and tap the link that pops up.




One of the many mechanisms that allow Bitcoin to function properly is the blockchain. As you may have discovered in the articles on the Bitstack blog, the blockchain makes it possible to avoid the double spending of the same bitcoin coin (what is called a UTXO).
As the name suggests, this blockchain is made up of blocks. In this article, we explore what Bitcoin blocks really are and how each block is built.
The blockchain is a register listing all Bitcoin transactions. It is used in the protocol so that each user is aware of past transactions. Thanks to this, we can prove the non-existence of a previous expenditure of bitcoins, and therefore avoid double spending.
This concept is very simply explained in the Bitcoin White Paper by Satoshi Nakamoto with the famous phrase:” The only way to confirm the absence of a transaction is to be aware of all transactions. ”
The objective of this register is thus to timestamp past transactions. In order to be able to put an hour on this information, we group them into blocks. Each block includes the fingerprint of the block preceding it in order to make them unchangeable, creating a kind of chain. This is why we speak of blockchain, or “blockchain” in English.

➤ Learn more about the role of blockchain in Bitcoin.
A Bitcoin block is mostly made up of two distinct parts. The first is its header, which contains 80 bytes of metadata. The second is the list of transactions executed.
Since the 2017 SegWit update, the size of a block is determined by a virtual unit called weight. The weight of a block is calculated by adding its real size, to three times its size, but without witnesses (signatures). The maximum limit is 4 million weight units. In theory, a Bitcoin SegWit block can therefore have a maximum real size of just under 4 MB. However, the actual average block size has normally fluctuated between 1 and 2 MB since 2017.
The arrival of the Ordinals protocol on Bitcoin at the beginning of this year 2023 affected this average to the rise. Since February, Bitcoin blocks have had a real average size of close to 3 MB.
The main part of a Bitcoin block is its header. When we talk about the fingerprint of a block, or its hash, it is indeed its header that we have passed twice in the SHA256 hash function.
To understand the composition of the header of a block, the best thing is to study a real one. Here is information on block No. 714 254, mined by F2Pool on December 15, 2021:
.png)
If you want to do the same on your Bitcoin node, run the “getblockheader” command followed by the fingerprint of the desired block on bitcoin-cli.
Thanks to this command, we discover several elements about the block studied. Not all of this information is included in the header. The real header of the block is composed of only 6 elements:

A Bitcoin block header contains only these 6 elements. The order getblockheader However, we receive other information that may be interesting to analyze, but that is not really part of the header itself:
Now that we have studied the first part of the block, i.e. its header, let's look at the second part of the Bitcoin block together.
Transactions in a Bitcoin block are not simply listed one after the other. Instead, they are organized into a cryptographic accumulator called a “Merkle tree.” This makes it possible to produce a Merkle root, which is a very small summary of all the transactions in the block.
Its principle is quite simple to understand. Each transaction is first passed through a hash function. The resulting hashes are concatenated two by two (i.e. put end to end). Then, they are passed through a hash function again. We continue this process like this until we get a single hash called “Merkle root.”
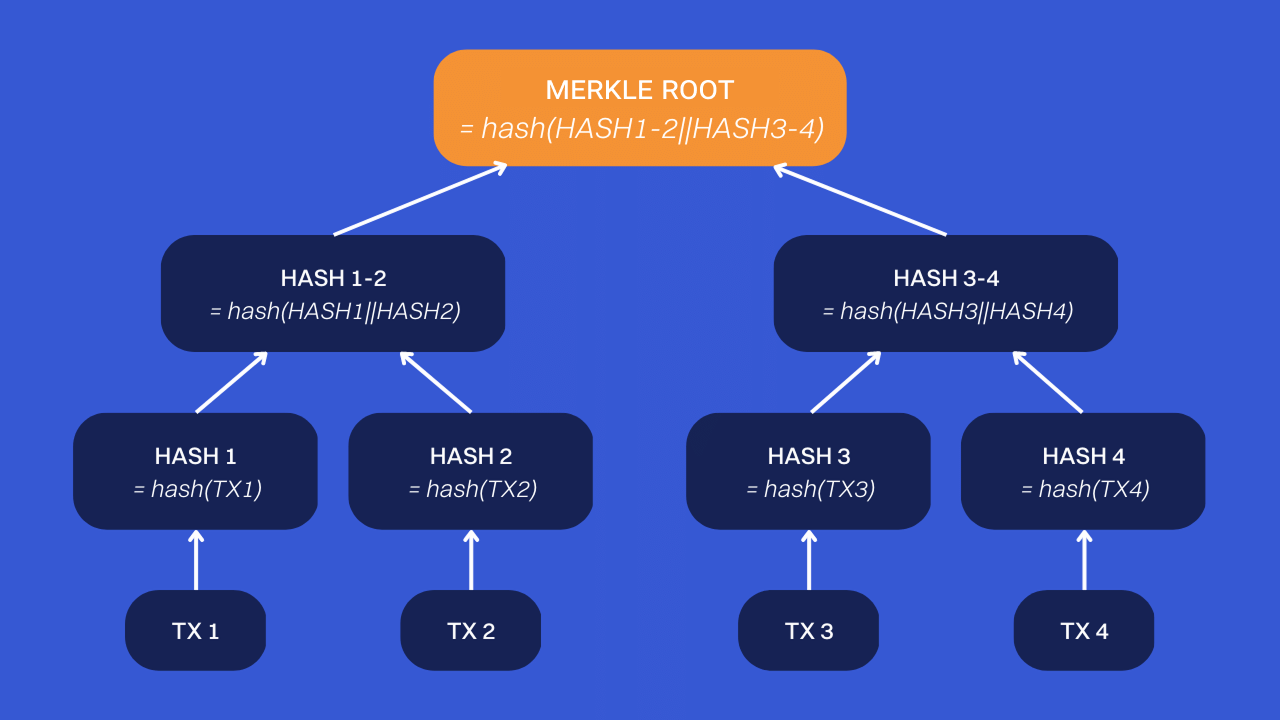
As seen previously, this Merkle root is then included in the block header. This allows all transactions to be represented in a condensed manner in the header. Thus, the slightest modification of a past transaction changes the Merkle tree, so it also changes the Merkle root, and therefore, it changes the block header and its footprint. Since this fingerprint is used in the next block, the slightest modification of a past transaction finally breaks the Bitcoin blockchain.
Since 2017 and the introduction of SegWit, Bitcoin blocks actually contain 2 Merkle trees. The first contains the transactions without their witness, and the second contains the witness for each transaction. The root of the second Merkle tree is included in the Coinbase transaction so that changes can be detected.
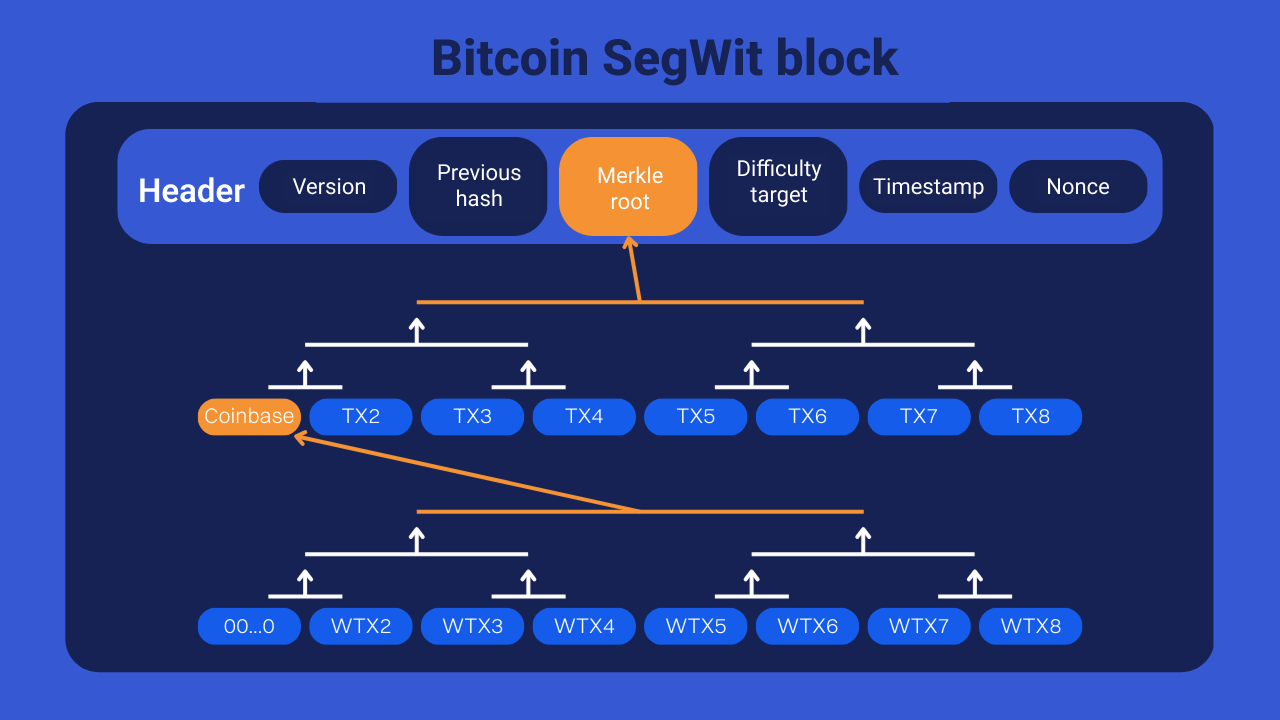
📌 The coinbase transaction is the first transaction in the Bitcoin block. It allows the winning miner to collect the bitcoins due to him as a reward for his mining work. It is composed of the coinbase reward, which issues new bitcoins, and the transaction fees included in the block.
This is where the name “SegWit” comes from, which is the acronym for “Segregated Witness”, which in French means “separate witness”.
In the diagram above, we can see that the witnesses, noted “WTX”, have their own Merkle tree. The root of this tree is put into the coinbase transaction. Transactions without their witnesses also have their own Merkle tree. The root of the second tree is put in the header of the block. So, all the parts of all the transactions in the block are condensed into the header.
Blockchain is used on Bitcoin to avoid double spending. It acts like a timestamp server. A block is therefore simply a grouping of Bitcoin transactions with some metadata. Its structure is mainly divided into two spaces: the header and the Merkle trees.
The header of a block is composed of 6 elements: the version, the imprint of the previous block, the Merkle root, the timestamp, the difficulty target and the nonce.
Transactions, on the other hand, are grouped together in a Merkle tree. This cryptographic accumulator produces a root that is incremented in the header of the block in order to link everything.






